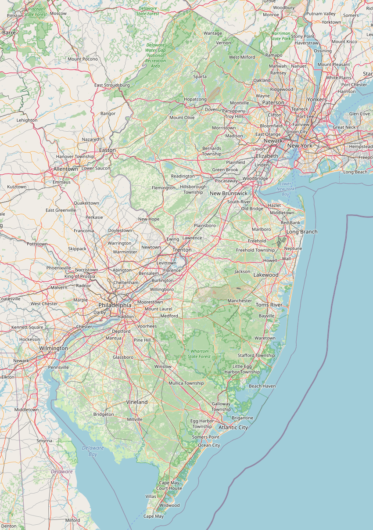
I have been working on a project that is driven by a series of functions written in PL/pgsql. The functions look at New Jersey’s land use data over several different time periods and selects out certain areas if they have the right mix of land use types and they meet an overall size threshold. The project requires the same selection process with approximately 60 different selection criteria and it operates over 5 different time periods of land use data. An efficient, programmatic approach to the problem is absolutely necessary.
Last night, I finished writing up a function to perform another set of steps in this selection process. As land use changes over time, the function creates 5 different sets of polygons based on the five time periods (1986, 1995, 2002, 2007, 2012) to represent the size thresholds the land use data must meet. After selecting the non-compliant areas, the function then marks the underlying land use as “not selected”, using a bitmask which represents selection/rejection for each time period. For example, I need to only include land use polygons where their contiguous area is greater than 50 acres. Individual polygons are going to be smaller than 50 acres, but should be included if they are part of a contiguous fabric of polygons that exceeds that size.
Before leaving work, I ran the function against some test data and when I arrived this morning I found the query was still running. It took 7 hours to complete the one step!
NOTICE: Generating patch polygons...
NOTICE: Applying constraint to patch polygons...
NOTICE: Applying bitmask to polygons that fail to meet size threshold...
NOTICE: Patch Size Requirement Constraint Complete.
NOTICE: Query execution time: 07:00:54.204277
query result with 1 row discarded.
The function that was causing the delay was that final update to the base data.
EXECUTE $$
UPDATE $$||tblbase||$$ b
SET transition_mask = transition_mask & '11110'::bit(5)
FROM $$||tblpatch||$$ patch
WHERE patch.period = 1986 AND patch.size_threshold = 0
AND ST_Intersects(patch.shape, b.shape)
;$$;
Keep in mind this is one of 5 functions for each of the time periods. What was causing it to run so slow? Well, the land use data is a conflation of all five time periods, weighing in at about 2.5 million polygons. I calculated a spatial index on both tables, but clearly that was not enough. Luckily, this data also has a region identifier. The land use data was split up into about 8,000 regions, each with its own unique region identifier. As the “patch” data was generated from the same land use, we could include the region identifier in that as well to help optimize the query. It was safe to use the region id, as no two polygons with different region ids would touch and be contiguous.
I modified the “patch” creation portion of the function to include the region identifier and then modified the function, like so:
EXECUTE $$
UPDATE $$||tblbase||$$ b
SET transition_mask = transition_mask & '11110'::bit(5)
FROM $$||tblpatch||$$ patch
WHERE patch.period = 1986 AND patch.size_threshold = 0
AND patch.newregionid = b.newregionid
AND patch.shape && b.shape AND ST_Intersects(patch.shape, b.shape)
;$$;
I also realized I was missing a step I used elsewhere in this project. The double-ampersand (&&) operator performs a minimum-bounding rectangle comparison between the two geometries. This operation can also be performed using only the spatial index. So I added it as well in the hopes that it would improve the results. Running the function again, the process now only takes about 15 minutes, which is approximately 28 times faster than before.
Here’s the EXPLAIN on the first version of the function:
Update on baseland b (cost=16.47..20972348.39 rows=4192474 width=526)
-> Nested Loop (cost=16.47..20972348.39 rows=4192474 width=526)
-> Seq Scan on curr_patch patch (cost=0.00..48093.89 rows=49087 width=1546)
Filter: ((period = 1986) AND (size_threshold = 0))
-> Bitmap Heap Scan on baseland b (cost=16.47..425.72 rows=34 width=520)
Recheck Cond: (patch.shape && shape)
Filter: _st_intersects(patch.shape, shape)
-> Bitmap Index Scan on sidx_baseland (cost=0.00..16.46 rows=101 width=0)
Index Cond: (patch.shape && shape)
And with the changes to the where clause:
Update on baseland b (cost=0.41..458738.64 rows=1 width=526)
-> Nested Loop (cost=0.41..458738.64 rows=1 width=526)
-> Seq Scan on curr_patch patch (cost=0.00..48093.89 rows=49087 width=1553)
Filter: ((period = 1986) AND (size_threshold = 0))
-> Index Scan using sidx_baseland on baseland b (cost=0.41..8.36 rows=1 width=520)
Index Cond: ((patch.shape && shape) AND (patch.shape && shape))
Filter: ((patch.newregionid = (newregionid)::text) AND _st_intersects(patch.shape, shape))
No longer are we relying on a Heap Scan, instead we use the spatial index, with both the text comparison and the more thorough ST_Intersects() to validate the results returned from the Index Scan. I’m still amazed that the query planner (this is on PostgreSQL 9.3.9 with PostGIS 2.1.7) doesn’t use the MBR/Index Scan when comparing features using ST_Intersects. It’s always good to run EXPLAIN against your queries and test them in isolation. Just because you generated an index, doesn’t mean the database is actually using it. And it might seem redundant to type a.shape && b.shape AND ST_Intersects(a.shape, b.shape), but I’m happy to do it if it saves hours of time waiting for tasks to complete.