
Often, when I go to tackle a problem, I look to use the simplest tools available first. Unix (and its derivatives/descendants, like Mac OS X and Linux) was designed with the following principles in mind:
Write programs that do one thing and do it well. Write programs to work together. Write programs to handle text streams, because that is a universal interface. —Doug McIlroy
One of my side projects is an index of property assessment records for New Jersey. The pages containing the property records all have the same URL structure:
/property/muncode/block/lot
Where the “muncode” is the 4 digit identifier for New Jersey municipalities published by the Division of Taxation, and the “block” and “lot” are the local level parcel identifiers. So each directory reflects essentially the spatial distribution of properties – lots will be near to other lots within the same block or municipal folder.
I recently wanted to see how each town was performing in terms of page views. Now, I can see such a report using the Content Drilldown in Google Analytics, but I really did not want to write something substantial to get at the information programmatically for further analysis.
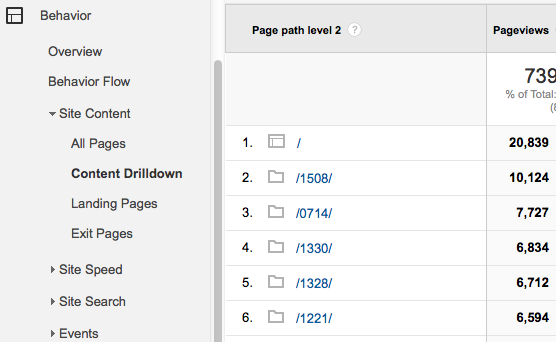
Content Drilldown in Google Analytics
Content Drilldown is available through the API, so I could write something that authenticates against the API, performs the queries and stores the results, but that would be overkill, considering I also have the access log from Apache at my disposal.
I was able to make a report similar to what is on Google Analytics by using several Unix tools. Here’s what I did in one line to get the same type of information.
$ grep -oP '/property/\d+' access_log | sort | uniq -c | sort -rn
12289 /property/1508
11226 /property/0714
9630 /property/1506
8272 /property/0906
8130 /property/1507
...
First, grep (globally search with regular expressions and print) will take in a file – in this case, “access_log” – and return only the portion of each line that matches the regular expression “/property/\d+“. The significant portion of that is the \d+ which means match one or more digits. Normally, grep returns the entire line when there is a match. The -oP are two flags to say only return the match and use Perl regular expressions.
If you’re not familiar with Unix, you may have once looked at your keyboard and thought, “what’s that vertical line and when would I ever need it?” The vertical line is often referred to as the “pipe” character, as it signifies that the output of one Unix tool should be passed (or piped) into the next tool written on the command line. With this, we can channel the results of a tool into the next tool for further processing.

The pipe character persists, even on an iPad keyboard.
We pipe the output of grep (a list of all second-order directories accessed by visitors) into sort. sort does what is sounds like, sorting each line returned alphabetically. We sort the output of grep to use the next tool to give us our count, uniq.
uniq collapses duplicate lines into one and can also provide a count of lines collapsed (using -c). In order for uniq to work properly, we need to sort the file first.
Finally, I sort the piped output one more time, now using the
r and n flags, which reverse the order and sort numerically instead of alphabetically, allowing me to see the most-visited municipalities at the top of my output.
I can further process these results, using other tools like awk and sed to perform other tasks, such as reformatting to CSV for loading into a database.
The Unix philosophy has always been in the back of my mind when working with Desktop GIS. The UIs are always so busy and complex that you often struggle with knowing what tool to use but being unable to find it. Or be stuck with the point-and-click mentality, where the tools expect human intervention in order to work. While concepts like ModelBuilder in ArcGIS Desktop are a step in the right direction, it still leaves much to be desired. Don’t get me wrong, I’m not suggesting we go back to AML, but we should put more thought into the tools that are available to us and use the ones that are best for the job. While I’m most at home programming in Python and could easily have written something in the language to parse the file and tally the results, it was ultimately much quicker to briefly experiment with existing tools and come up with a solution.
The right tools aren’t always the familiar ones, but you might become more familiar with them with some experimentation.